How does GBM algorithm work
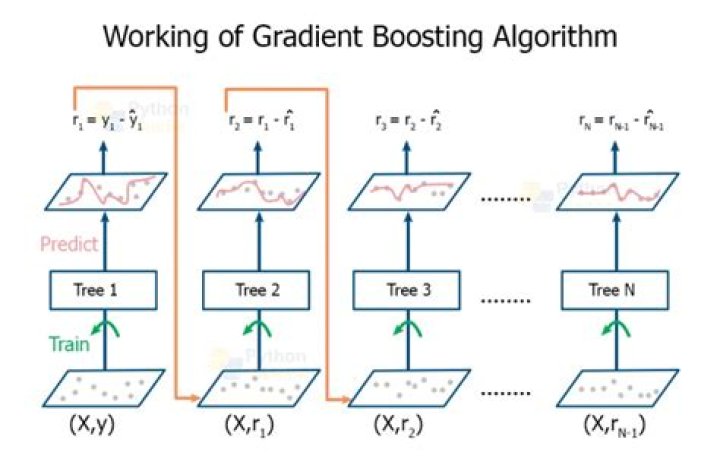
The gradient boosting algorithm (gbm) can be most easily explained by first introducing the AdaBoost Algorithm. The AdaBoost Algorithm begins by training a decision tree in which each observation is assigned an equal weight. … Gradient Boosting trains many models in a gradual, additive and sequential manner.
How does a GBM model work?
As we’ll see, A GBM is a composite model that combines the efforts of multiple weak models to create a strong model, and each additional weak model reduces the mean squared error (MSE) of the overall model. We give a fully-worked GBM example for a simple data set, complete with computations and model visualizations.
How do gradient boosted trees work?
In case of gradient boosted decision trees algorithm, the weak learners are decision trees. Each tree attempts to minimize the errors of previous tree. … Since trees are added sequentially, boosting algorithms learn slowly. In statistical learning, models that learn slowly perform better.
How does the gradient boosting algorithm work?
Gradient boosting is a type of machine learning boosting. It relies on the intuition that the best possible next model, when combined with previous models, minimizes the overall prediction error. … If a small change in the prediction for a case causes no change in error, then next target outcome of the case is zero.How does gradient boosting Regressor work?
Gradient boosting algorithm can be used for predicting not only continuous target variable (as a Regressor) but also categorical target variable (as a Classifier). When it is used as a regressor, the cost function is Mean Square Error (MSE) and when it is used as a classifier then the cost function is Log loss.
Is Random Forest bagging or boosting?
The random forest algorithm is actually a bagging algorithm: also here, we draw random bootstrap samples from your training set. However, in addition to the bootstrap samples, we also draw random subsets of features for training the individual trees; in bagging, we provide each tree with the full set of features.
What is CatBoost algorithm?
CatBoost is an algorithm for gradient boosting on decision trees. It is developed by Yandex researchers and engineers, and is used for search, recommendation systems, personal assistant, self-driving cars, weather prediction and many other tasks at Yandex and in other companies, including CERN, Cloudflare, Careem taxi.
How can I improve my glioblastoma performance?
- Choose a relatively high learning rate. …
- Determine the optimum number of trees for this learning rate. …
- Tune tree-specific parameters for decided learning rate and number of trees. …
- Lower the learning rate and increase the estimators proportionally to get more robust models.
Why is Xgboost faster than GBM?
Both xgboost and gbm follows the principle of gradient boosting. There are however, the difference in modeling details. Specifically, xgboost used a more regularized model formalization to control over-fitting, which gives it better performance.
What does gradient mean in gradient boosting?In short answer, the gradient here refers to the gradient of loss function, and it is the target value for each new tree to predict.
Article first time published onWhat is learning rate in GBM?
GBM parameters The learning rate corresponds to how quickly the error is corrected from each tree to the next and is a simple multiplier 0<LR≤1. For example, if the current prediction for a particular example is 0.2 and the next tree predicts that it should actually be 0.8, the correction would be +0.6.
How does the gradient boosted trees model ensemble the results of many decision trees?
Gradient Boosted Trees and Random Forests are both ensembling methods that perform regression or classification by combining the outputs from individual trees. They both combine many decision trees to reduce the risk of overfitting that each individual tree faces.
How is CatBoost algorithm implemented?
- Import the libraries/modules needed.
- Import data.
- Data cleaning and preprocessing.
- Train-test split.
- CatBoost training and prediction.
- Model Evaluation.
Is CatBoost supervised or unsupervised?
CatBoost is an open source, Gradient Boosted Decision Tree (GBDT) implementation for Supervised \text {ML} bringing two innovations: Ordered Target Statistics and Ordered Boosting.
Why you should learn CatBoost now?
Not only does it build one of the most accurate model on whatever dataset you feed it with — requiring minimal data prep — CatBoost also gives by far the best open source interpretation tools available today AND a way to productionize your model fast.
Does bagging eliminate Overfitting?
Bagging attempts to reduce the chance of overfitting complex models. It trains a large number of “strong” learners in parallel. A strong learner is a model that’s relatively unconstrained. Bagging then combines all the strong learners together in order to “smooth out” their predictions.
Does bagging use weak learners?
Bagging is a homogeneous weak learners‘ model that learns from each other independently in parallel and combines them for determining the model average. … In this model, learners learn sequentially and adaptively to improve model predictions of a learning algorithm.
Does random forest Underfit?
When the parameter value increases too much, there is an overall dip in both the training score and test scores. This is due to the fact that the minimum requirement of splitting a node is so high that there are no significant splits observed. As a result, the random forest starts to underfit.
Why LightGBM is fast?
LightGBM is called “Light” because of its computation power and giving results faster. It takes less memory to run and is able to deal with large amounts of data. Most widely used algorithm in Hackathons because the motive of the algorithm is to get good accuracy of results and also brace GPU leaning.
Is GBM better than random forest?
If you carefully tune parameters, gradient boosting can result in better performance than random forests. However, gradient boosting may not be a good choice if you have a lot of noise, as it can result in overfitting. They also tend to be harder to tune than random forests.
Why is LightGBM so good?
Advantages of Light GBM Faster training speed and higher efficiency: Light GBM use histogram based algorithm i.e it buckets continuous feature values into discrete bins which fasten the training procedure. Lower memory usage: Replaces continuous values to discrete bins which result in lower memory usage.
Is gradient boosting supervised or unsupervised?
Gradient boosting (derived from the term gradient boosting machines) is a popular supervised machine learning technique for regression and classification problems that aggregates an ensemble of weak individual models to obtain a more accurate final model.
What is shrinkage in gradient boosting?
Shrinkage is a gradient boosting regularization procedure that helps modify the update rule, which is aided by a parameter known as the learning rate. The use of learning rates below 0.1 produces improvements that are significant in the generalization of a model.
What is shrinkage in GBM?
In the context of GBMs, shrinkage is used for reducing, or shrinking, the impact of each additional fitted base-learner (tree). It reduces the size of incremental steps and thus penalizes the importance of each consecutive iteration.
Can boosting overfit?
All machine learning algorithms, boosting included, can overfit. Of course, standard multivariate linear regression is guaranteed to overfit due to Stein’s phenomena. If you care about overfitting and want to combat this, you need to make sure and “regularize” any algorithm that you apply.
How do you speed up a gradient boosting classifier?
To accelerate the gradient-boosting algorithm, one could reduce the number of splits to be evaluated. As a consequence, the generalization performance of such a tree would be reduced. However, since we are combining several trees in a gradient-boosting, we can add more estimators to overcome this issue.
Is GBM a decision tree?
The gradient boosting algorithm (gbm) can be most easily explained by first introducing the AdaBoost Algorithm. The AdaBoost Algorithm begins by training a decision tree in which each observation is assigned an equal weight. … Gradient Boosting trains many models in a gradual, additive and sequential manner.
When you use the boosting algorithm you always consider the weak learners Which of the following is the main reason for having weak learners?
26) When you use the boosting algorithm you always consider the weak learners. Which of the following is the main reason for having weak learners? To prevent overfitting, since the complexity of the overall learner increases at each step.
How do you use a CatBoost classifier?
- Step 1 – Import the library. …
- Step 2 – Setup the Data for classifier. …
- Step 3 – Model and its Score. …
- Step 4 – Setup the Data for regressor. …
- Step 5 – Model and its Score.
What is ordered boosting in CatBoost?
Ordered Boosting: As a solution to prediction shift, CatBoost samples a new dataset independently at each step of boosting to obtain unshifted residuals by applying the current model to new training examples. … This is achieved using a random permutation σ of the training examples.
